


Next: Track evaluation
Up: Algorithms
Previous: Hit resolution
The hit merging algorithm uses only the space point information for the
hits. It was decided, in the interest of speed, to not use the pad structure.
A cluster of hits is found by numbering all the hits in a pad row.
Then on each pass through every hit is compared to every other hit,
if the two hits are within the merging distances
(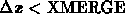 and
and 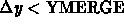 , or
, or
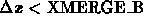 and
and 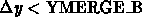 )
the hit numbers are compared, if they are
different, then the larger hit number is set to the lower hit number.
After sufficient passes, the hit number of the lowest hit in a cluster
will propagate throughout the entire cluster and identify hits in the
cluster. Sufficient passes is the
number of hits in the largest cluster (in the pad row) minus one, since
on each pass at least one number must change, and the number of the lowest
hit will not be changed. The program uses as an upper bound the number of
hits in the pad row, and uses a flag to watch for the case that no hit
numbers were changed (which indicates the end of the cluster finding).
Note that this algorithm allows clusters of arbitrary size and shape.
The size
of the cluster (
)
the hit numbers are compared, if they are
different, then the larger hit number is set to the lower hit number.
After sufficient passes, the hit number of the lowest hit in a cluster
will propagate throughout the entire cluster and identify hits in the
cluster. Sufficient passes is the
number of hits in the largest cluster (in the pad row) minus one, since
on each pass at least one number must change, and the number of the lowest
hit will not be changed. The program uses as an upper bound the number of
hits in the pad row, and uses a flag to watch for the case that no hit
numbers were changed (which indicates the end of the cluster finding).
Note that this algorithm allows clusters of arbitrary size and shape.
The size
of the cluster (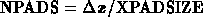 ) is compared
to a cut (XMAX_CLUSTER_SIZE) and it is not output if it is too large.
) is compared
to a cut (XMAX_CLUSTER_SIZE) and it is not output if it is too large.
The hit that is the result of the merging has the following parameters
associated with it:
-
GEANTID, the GEANTID of the hit that contributed
the most energy to the cluster.
-
TRACKID, this is not used.
-
PADROW, all the pad rows in a cluster are the same so the first is used.
-
NPADS, this is set to the cluster size in x divided by the pad width.
-
SATF, this is not used.
-
DECON, this is not used.
-
X, this is set to the weighted (by DEDX_ARE) average of the X's in the cluster.
-
Y, this is set to the weighted (by DEDX_ARE) average of the Y's in the cluster.
-
Z, this is set to the weighted (by DEDX_ARE) average of the Z's in the cluster.
-
DX, this is set to the sum, in quadrature, of the variance of the hits in the
cluster, and the (weighted sum of the) DX's of the hits in the cluster
-
DY, this is set to the sum, in quadrature, of the variance of the hits in the
cluster, and the (weighted sum of the) DY's of the hits in the cluster
-
SIGMA_PRF, this is unused.
-
DEDX_AMPL, this is set to the largest DEDX_AMPL of all the hits in the cluster.
-
DEDX_ARE, this is set to the sum of the DEDX_ARE in the cluster.
-
ALPHA, this is not used.
-
LAMBDA, this is not used.
-
XDEV_FIT, this is not used.
-
YDEV_FIT, this is not used.
These values overwrite the first hit in the cluster. The remaining
hits are flagged ``invalid.''
The sum that is taken for the DX is (taking 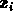 as the X for the hits and
as the X for the hits and
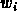 as the DEDX_ARE for the hits):
as the DEDX_ARE for the hits):
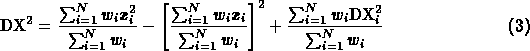
and the sum for DY is similar. Note that the first two terms are just
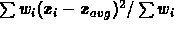 which is what the
hit finder will calculate if it is unable to resolve the hits.
which is what the
hit finder will calculate if it is unable to resolve the hits.
Next: Track evaluation
Up: Algorithms
Previous: Hit resolution
E895 common account
Wed Aug 6 16:32:35 EDT 1997